Lessons learned from attempting to launch a startup.

In Fall 2017, I made the decision to walk down the entrepreneurial path and dedicate a full-time effort towards launching a startup venture. I secured a healthy seed round of funding from a local angel investor and recruited three of my peers to join me in this effort. By Summer 2018, we decided to put the project on an indefinite pause. This blog post discusses what I set out to accomplish, what happened, and what I've learned from the experience.
The big idea
The venture was founded on a simple premise: we could use machine learning to forecast short-term fluctuations in market prices based on volume imbalances in order books.
Specifically, we were focused on the cryptoasset markets as these exchanges offered free, real-time data feeds to the order books and fulfilled trades.
An order book essentially maintains current unfulfilled orders for a given asset. The exchanges reference these order books in order to match interested buyers and sellers. If you're interested in trading something, you would publish your intentions to this order book which would be executed according to the type of order placed. New orders which can be matched with an existing order on the book are executed immediately and remove that volume from the order book.
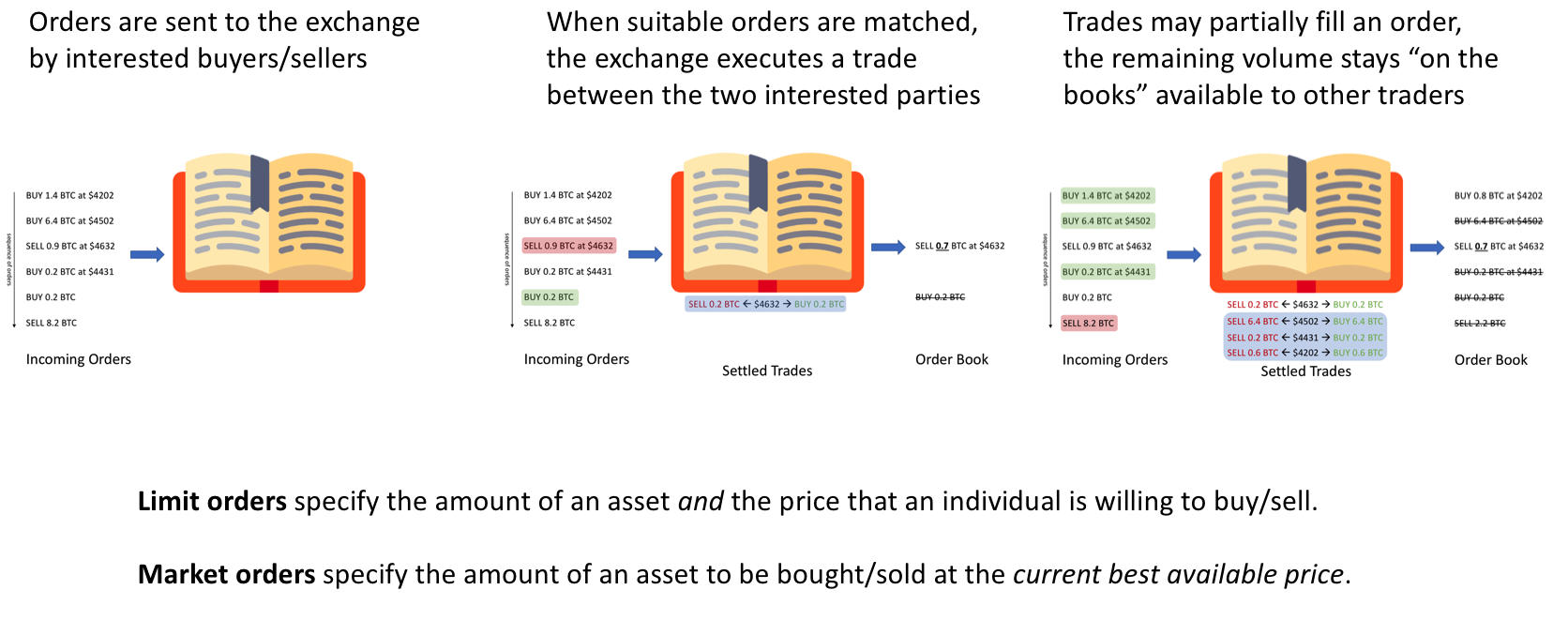
To gain an understanding for how this order book works, you can reference the following cartoon.
An illustrated guide to exchange order books

Because the order book contains a collection of orders waiting to be matched, it essentially displays the schedule for supply and demand as a function of price. That is, you can see how many people have stated that they are willing to buy/sell when the asset moves to a given price. The market price changes when the volume at the "best available price" level is exhausted.
As I watched how the order book and market prices evolved over a period of time, I began to notice predictable patterns emerge.

Feel free to check out a live feed of the BTC-USD order book and see if you can spot any of the patterns mentioned alongside the corresponding price action.
It's also worth noting that cryptoassets are a unique asset class given that the underlying assets being traded are publicly inspectable in real-time. For example, you can listen in on the Bitcoin network and capture statistics such as the number of participants in the network, the total value being transacted on the network, and other useful metrics. Compare this to a US public equity which only releases internal information about the company in their quarterly reports. Given this radical openness and transparency, the asset class seems uniquely posed for quantitative, data-driven trading.
After securing funding and recruiting a team, we initially budgeted 2 to 3 months to build an initial proof of concept and further evaluate the feasibility of the idea.
Building the proof of concept
As we set out to build the proof of concept, the initial days consisted of architecting and clarifying the exact needs and requirements of our technical infrastructure. We discussed various machine learning models and approaches, and specified the desired characteristics of our models. Because the cryptoasset market is rapidly evolving, we wanted models which supported continuous "online" learning. We also posited that this would help safeguard our models from being manipulated by bad actors who could "spoof" the order book data; a model capable of continuous learning could evolve to not be susceptible to repeated manipulation attempts.
As the weeks passed, we unknowingly succumbed to scope creep as our designs for a minimum viable product inched closer toward designs for a robust scalable product. I've realized the importance of building forcing functions into projects to specifically protect against scope creep.
Looking back, it's now clear that we had operated under the naive assumption that our fundamental hypothesis was correct (after all, it seemed like it was the right idea) which led us to focus our time addressing auxiliary problems such as scalability and performance optimizations. If we had instead focused all of our energy on testing our riskiest (fundamental) assumption, we would have discovered its flaws much more quickly.
Discovering flaws in our fundamental assumption
After spending a fair amount of time designing and iterating on our data infrastructure, we settled down to perform some more rigorous analysis of the data being collected by the real-time market feeds.
Here's what we learned:
- Most of the observed price fluctuations were too small to be profitable after accounting for trading fees.
- The data was highly imbalanced, where most periods of time the proper action was no action. When looking at snapshots of the order book once per second, profitable buy and sell opportunities were observed in ~2% of the snapshots.
- The signal wasn't as clear as it seemed. When I had manually been watching the exchange data for patterns, I was subject to confirmation bias where I was only attune to the patterns when they did manifest, not when they didn't. The order book data in fact contains quite a bit of noise as traders can cancel their orders at any given time.
For machine learning models, datasets that are inherently more difficult to learn from see an amplification in the learning challenge when a class imbalance is introduced.
The initial hypothesis was that we could use machine learning to forecast short-term price fluctuations based on the order book data. After validating the idea, we concluded that the idea was not likely feasible, at least not in the continuous, automated fashion we had imagined with machine learning.
I had started working on this problem as a side project as I was looking to apply what I have been learning about (machine learning) to address a messy, real world problem. The problem was attractive as it appeared to offer a wealth of data which was freely accessible - however, I did not accurately gauge the challenge of learning from this firehose of market data.
Moving forward
When we discovered the flaws in our fundamental assumption, we had two main options: pivot or halt the project. After much deliberation, we eventually decided to halt this project. We each had our own reasons for reaching this conclusion, I'll only discuss my personal reasons.
At this stage in life, I’m focused on optimizing for learning and continuing to invest in myself. I’ve realized that your environment is a critical factor in this growth, so I’ve decided to embed myself in an environment where I can work alongside more senior engineers and gain experience working with teams who have a history of building machine learning products.
I'm 22 years old, I have a long career ahead of me. My insatiable desire to build things has cultivated an interest in both engineering and entrepreneurship, and I'm sure I'll walk down the entrepreneurial path once again later in my career. However, my current focus is on mastering machine learning and gaining practical work experience; I feel as if this focus will be beneficial for the long-term trajectory of my career.
"The average age of founders of the most successful startups—those with growth in the top 1% of their industry—was 45." Source
I learned a lot my from experience exploring this venture and I'm grateful for the challenges that I encountered. Here's to the next adventure.