Machine learning overview.

Preface: this post is for the complete novice in the field of machine learning in an attempt to orient readers for my other posts on machine learning. This is a high-level view of machine learning.
What the heck is machine learning?
The whole concept of machine learning is figuring out ways in which we can teach a computer to perform a task without needing to provide explicit instructions. Another way to think about it is that we're trying to "program" intuition in a computer. You and I can look at an email and easily discern whether or not it's spam, but how do you get a computer to do such a task? You could construct a huge convoluted logic infrastructure of "if.. then.." statements to sort out the spam emails, but it would be a pain to construct and probably wouldn't work too well. Instead, the machine learning approach is to equip the computer with skills to learn on its own and feed it a bunch of examples. Machine learning is exploding as a field right now as people are realizing a multitude of tasks that we can teach computers to perform by feeding it large datasets.
The general machine learning framework
Machine learning isn't one singular tool, it's an entire field of tools - each with their own strengths and weaknesses. The way we allow computers to learn is by providing it with a model which serves as the learning framework. The image below is a guide from scikit-learn (a collection of Python implementations of various machine learning algorithms and functions) on selecting the proper model for your machine learning application. Part of being a machine learning expert is knowing which tool to use!
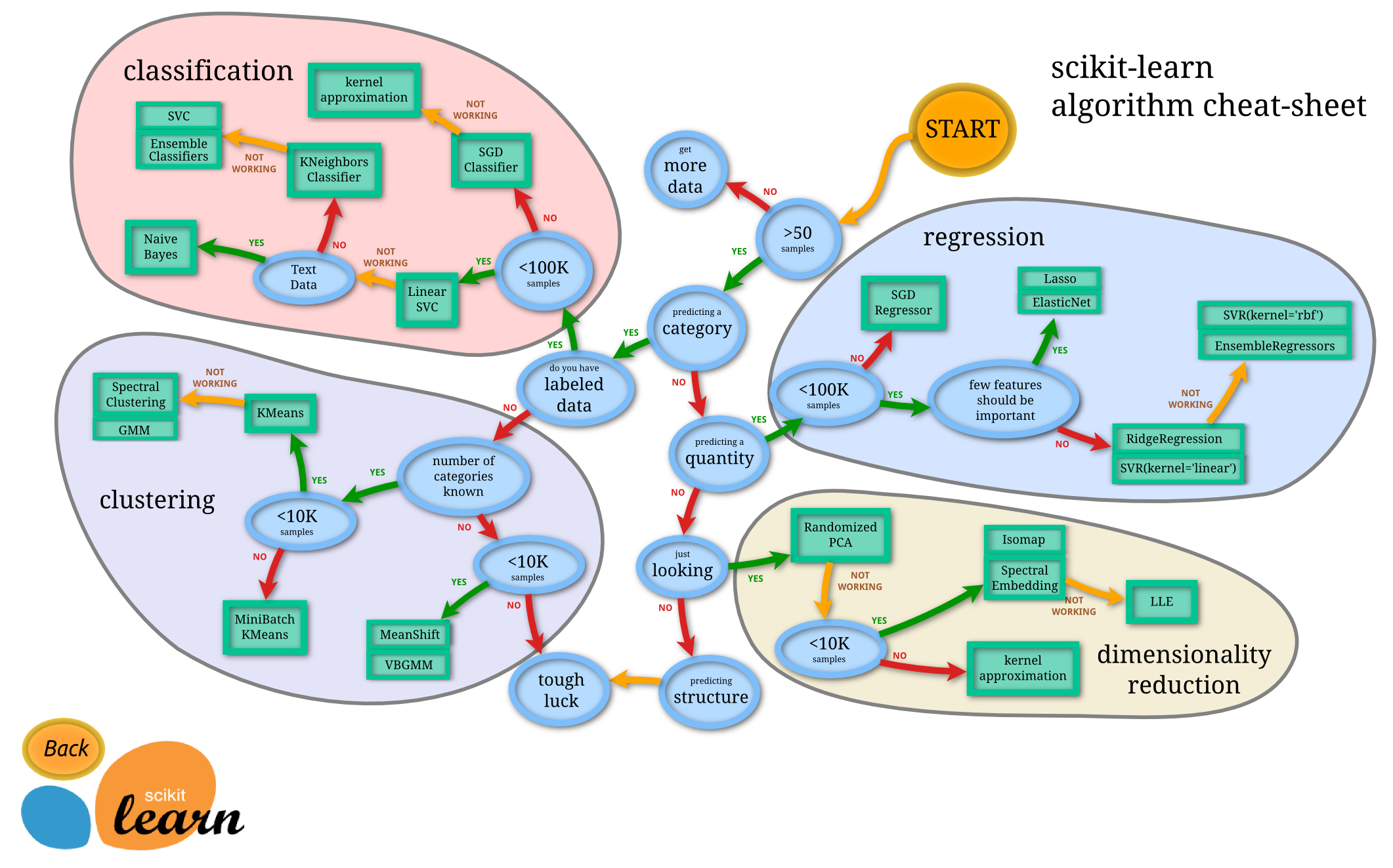
Once you've selected your model, you typically follow the same general procedure.
- Preprocess your data so that it will feed properly into your model.
- Construct your model.
- Train your model on a dataset and tune all relevant parameters for optimal performance.
- Evaluate your model and determine its usefulness.
I'll be writing in more detail about each of these steps in following blog posts.
So as a reminder, rather than explicitly programming the computer to complete a task, we're providing a ton of examples (data) for the computer to learn from with the goal of completing some given task. There are times when we tell the computer what we want it to do (by training it on a dataset with predefined outputs) and there are times when we simply hand over a dataset to the computer and ask it to discover something on its own. When we train a computer by providing it with data that has predefined outputs, we call this supervised learning. An example of this would be training a spam filter for your email by giving the algorithm a huge set of example emails which are labeled as "spam" or "not spam". When we simply hand over a dataset to the computer and ask it to find something interesting, this is known as unsupervised learning, since we're not telling the computer what output we'd like to see. Unsupervised machine learning techniques are ideal because it takes time to label datasets for training supervised models. There's also such thing as semi-supervised learning where we leverage a small dataset of labeled observations combined with a much larger dataset of unlabeled observations to use in training a model to perform some task.
Machine learning algorithms are capable of tasks such as classifying objects found in photos, predicting the optimal price to sell your house with regression, customer and market segmentation using clustering techniques, and much much more. Pretty cool, huh?
Further reading
Bonus: A Massive Google Network Learns To Identify — Cats
For a detailed look at the impact of machine learning on businesses, check out the following article from Harvard Business Review.
The Great A.I. Awakening: How Google used artificial intelligence to transform Google Translate, one of its more popular services — and how machine learning is poised to reinvent computing itself.