Building machine learning products: a problem well-defined is a problem half-solved.
Previously, I wrote about organizing machine learning projects where I presented the framework that I use for building and deploying models. However, that framework operates on the implicit assumption that you already know generally what your model should do.

Previously, I wrote about organizing machine learning projects where I presented the framework that I use for building and deploying models. However, that framework operates on the implicit assumption that you already know generally what your model should do. In this post, we'll dig deeper into how to develop the requirements for a machine learning project when you're given a vague problem to solve. Some questions that we'll address include:
- What specific task should our model be automating?
- How does the user interact with the model?
- What information should we expose to the user?
Note: Sometimes machine learning projects can be very straightforward; your stakeholders define an API specification stating the inputs to the system and the desired outputs and you agree that the task seems feasible. These projects typically support existing products with existing "intelligence" solutions - your task is to simply encapsulate the "intelligence" task using machine learning in lieu of the existing solution (ie. rule-based systems, mechanical turk workers, etc).
Throughout this blog post, I'll use the following problem statement as a running example.
We're building an application to help people keep their photos organized. Our target user base are casual smartphone photographers who have a large number of photos in their camera roll. We want to make it easier for these users to find photos of interest.
Notice how vague that problem statement is - what defines a photo of interest? There's a multitude of ways we could address this task and without understanding the problem in more detail we won't know which direction to take. At this point in time, we have insufficient information to specify an objective function for training a model.
Understanding the problem and developing the requirements isn't something you typically get right on the first attempt; this is often an iterative process where we initially define a set of coarse requirements and refine the detail as we gain more information.

Jump to:
- Understand the problem from the perspective of the user
- Mock out your machine learning model and iterate on the user experience
- Develop a shared language with your project stakeholders
- Win by shipping
- Conclusion
Understand the problem from the perspective of the user.
The first step towards establishing any set of requirements for a project is understanding the problem you're setting out to solve. No one knows the problem better than the intended user - the person we are attempting to solve the problem for.
Perform informational interviews with end users to understand their perspective. The further removed you are from the end user, the less likely you are to solve the actual problem they're experiencing.
Do you remember playing the telephone game as a kid, where you have a chain of people and try to deliver a message from one end to the other by asking each person to transmit the message to the person next to them? Usually the message at the end is very different from the original message. In order to ensure you're solving the right problem, you'll want to be able to empathize with the people who currently experience that problem.
For the case of our photo app example, this would involve speaking with casual smartphone photographers and understanding how they use their app.
- When they're searching through their camera roll, what are they typically looking for?
- Are they Instagram influencers who take 100 photos of the same thing and are trying to find the best photo to post?
- Are they nature photographers looking to share the scenic views from their latest camping trip?
- Are they recent parents trying to document the development of their newborn baby?
- Are they often looking for photos with a specific friend to share on social media with a happy birthday wish?
- What are their current strategies for finding the photos of interest?
- Do they know when the photo was taken?
- Do they flip through their camera roll photo by photo or scroll through a series of thumbnails?
- Are they typically searching for a photo of a specific person?
- Do they mentally "chunk" photos together and search chunk by chunk? What's the criteria for chunking?
At this stage you don't want to start prescribing a solution, you're simply trying to understand the problem. However, it can be good to consider the capabilities of machine learning systems and ask questions which may eventually guide your scoping of a solution. For example, let's consider the motivation behind asking the first set of questions.
- Are they Instagram influencers who take 100 photos of the same thing and are trying to find the best photo to post? Perhaps we want to consider clustering similar photos and then applying a ranking model to help them find the best photo to share.
- Are they nature photographers looking to share the scenic views from their latest camping trip? Do we need to consider additional metadata such as the GPS coordinates of where the photo was taken to enrich the data representation?
- Are they recent parents trying to document the development of their newborn baby? Perhaps we want to perform action recognition on the photographs to help the parents find the moment where their newborn walked for the first time or did a cute dance.
- Are they often looking for photos with a specific friend to share on social media with a happy birthday wish? Maybe we'll need to use facial recognition to identify the user's friends.
Even though you might be considering solutions, it's important that the conversations with users are focused on the problems they experience. You won't ask them about their thoughts on specific solutions until the next stage.
Subject yourself to the problem. As a machine learning practitioner, it can be tempting to jump right into training a model to learn some task. However, it's often very instructive to first force yourself to perform the task manually. Additionally, this helps you empathize with the users. Pay close attention to how you solve the task, as this might inform what features might be important to include when you do train a model to perform the task.
For example, after speaking with some casual smartphone photographers you might construct a couple photo albums and go through the tasks described during your interviews. What strategies did you find effective for finding content more quickly?
Mock out your machine learning model and iterate on the user experience.
After (and only after) getting a better understanding of the problem, you'll want to start sketching out the set of possible solutions and approaches that you could take. It's generally a good idea to think broadly at this stage rather than prematurely honing in on your first decent idea. At this stage, we're trying to elicit the desired user experience, as this can ultimately drive the requirements of the project.
Prototype and iterate on the user experience using design tools to communicate possible solutions. There's something magical about seeing something concretely that has the ability to elicit tangible feedback from your users. When speaking in the abstract sense, it's possible for both you and the other stakeholders to have different understandings whilst under the illusion that you're in agreement. However, these latent misunderstandings often become very clear when you reduce an abstract idea to practice.
For example, I used a design tool called Figma to sketch out a couple different ways we might help users find photos of interest more quickly. The goal of these sketches is to spark discussion with our stakeholders and/or users in an attempt to start narrowing down the possible solution space.
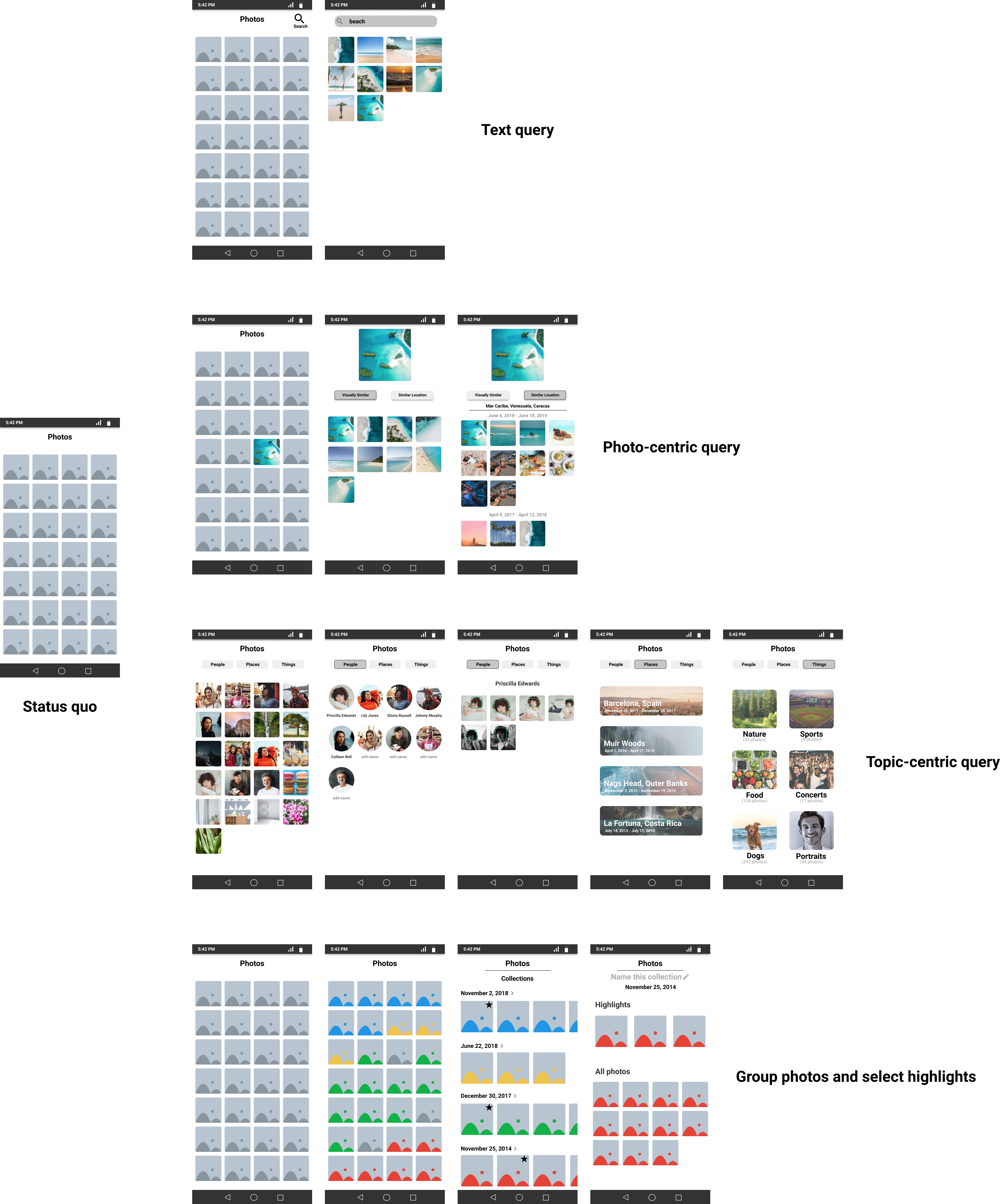
These tools allow you to easily stitch together user flows and import data to use in your mockups.
Fake the machine learning component with "Wizard-of-Oz" experiments. Building a machine learning model takes a significant amount of work. You have to acquire data for training, decide on a model architecture, ensure the model is performing at a sufficient level, etc. Our goal here is to validate the utility of a model without actually going through all of the effort involved in building it. These types of experiments can be especially useful when there's still uncertainty surrounding how users will interact with your model.
Apple researchers wrote about one such study when deciding whether their digital assistant should mimic the conversational style of the user. Their core hypothesis was that users would prefer digital assistants that match their level of chattiness when conversing with the agent. Rather than training a machine learning model that would allow them to modulate the "chattiness" level in the agent's response, they first tested this hypothesis by faking the digital assistant component and having humans in a separate room follow a script pretending to be the digital assistant.
Figure out how to establish trust with the user. Ideally you'd like to design your product such that user interactions can improve your model, which in turn improve the user experience. This is commonly referred to as the "data flywheel" in machine learning products. However, in order to source meaningful interactions from your users, you may need to first establish trust with the user that those interactions will indeed improve their experience. For example, if we decided that we would perform facial recognition and allow you to search for photos with a specific person present, you'd likely require the user to assign identities to collections of photos with a common face. In order to motivate and incentivize users, they need to feel as if their effort in identifying faces in photos is meaningful. One common technique used here is to show the model's effort in an unobtrusive manner which informs the user how it's working. Continuing the facial recongition example, you might allow the user to toggle a setting which draws bounding boxes around the identified faces in photos.

Develop a shared language with your project stakeholders.
At this point, you're likely to have a decent grasp on the approach you'll take to solve the presented problem. However, much work still lies ahead! It'll be important that you communicate effectively with stakeholders as you work to build out your solution; this starts with speaking a common language.
Perhaps a number of users leverage a technique of chunking photos together when searching, while you typically refer to that same technique as clustering. Without converging on a shared language, it's all too easy to talk right past one another without realizing you're actually on the same page.
Over-communicate and ask a lot of clarifying questions at the onset. This can include asking questions when you're already pretty sure what the answer will be, sometimes you may be surprised.
Present ideas and progress often. It's important to share progress with your stakeholders and hold discussion to ensure you're still heading in the right direction. As you present your work, it can be helpful to discuss things such as model metrics which you're using to evaluate performance and why we should care about those metrics; keeping things simple combined with repeated exposure can go a long way here.
Win by shipping.
Getting your product in the hands of your users is one of the best ways to validate your ideas. Quicker iterations allow you to validate more ideas, which in turn allows you to fine-tune your solution offering in order to maximize value to the user. Further, incremental deployments help ensure that you're heading in the right direction as you work to build out the full solution.

In my post on organizing machine learning projects, I presented a diagram for model development which represents the iterative nature of the work.

I also called out Stephen Merity's advice and Martin Zinkevich's Rule #4 of Machine Learning, which both advocate for initially deploying simple models in the spirit of winning by shipping. In this context, "winning by shipping" involves making quick iterations through the outermost development loop.
It can take getting a few projects under your belt to fully appreciate this wisdom. When I initially published the diagram a year ago, I tended to view progression through this iterative flow as a stage-gate process where you might loop back to an earlier step if you gain more information, but you still advance through the cycle in the order that sections appear on the diagram. However, after joining the machine learning team at Proofpoint, I've learned from the team that there can be immense value in shortcutting parts of the development process (eg. see shadow mode deployment below) in order to gain insights from deploying models on production data.
Deploy a baseline model on production data as soon as possible. Deploying your model on production data can be enlightening. Often times, the "live data" varies in unexpected ways from the data you've collected to use during development (often referred to as "train/test skew" or "production data drift").
As a countermeasure, it's often a good idea to deploy a simple model on production data as soon as possible. Depending on the consequence of wrong predictions, you might choose to deploy this simple model in "shadow mode" (don't actually use the predictions) or as a canary deployment on a small subset of your users. The goal of this deployment is to observe and characterize the types of errors that the simple model makes, which can inform further model improvements.
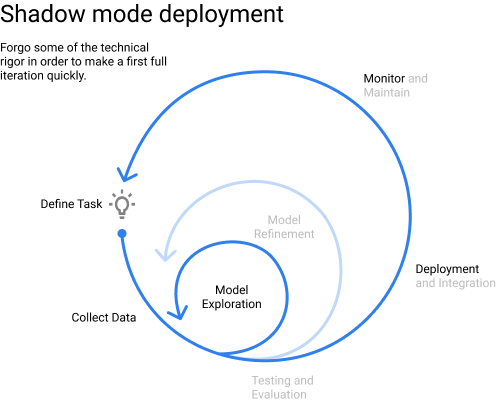
You may choose to initially skip some steps in the model development process in order to prioritize a quick first iteration and gain insights.
Deploying a simple model with urgency also helps ensure that the additional engineering work required to run a machine learning model is done upfront. This allows you to deploy your incremental model improvements (enabling quick iterations) rather than slaving away trying to build the perfect model in isolation.
Deliver value incrementally and quickly. If you're automating a system, start with the simplest task and deploy a solution quickly. Let data guide the priority order of further automation. In other words, automate first according to the "happy path" (assume nothing goes wrong) and then categorize the times where control is reverted to a human.
Going back to our photo app example, there are many opportunities to apply machine learning models to the product. Ideally, we'd like to start at the intersection of a model which is simple to develop and provides value to users. For example, we might decide to initially deploy a facial recognition model given the fact that there are a number of open source implementations that we could use and user studies provided us with some level of evidence that this model would be valuable as part of the product.
Measure time to results, not results. Sometimes it can be tricky to get into the mindset of delivering value quickly. It's easy to think that in order to delight the user, we need to give them the perfect product. Measuring time to results rather than the results themselves instills a culture of quick iterations which ultimately enables your team to deliver better products, winning by shipping.
Conclusion
Often times we're presented with vague problems and tasked with developing a "machine learning solution." By spending the effort to properly scope your project and define its requirements up front, you can establish a foundation for smooth iterations through the model development loop as we work towards a final solution.

Now go build great things!
The insights shared in this blog post are shaped by my experience working on teams building and deploying machine learning models in products. On my current team at Proofpoint, we frequently discuss how we can refine our process to deliver value quickly on machine learning projects; these conversations and shared experiences are invaluable. Thank you to John Berryman, Dan Salo, John Huffman, and Michelle Carney for reading early drafts of this post and providing feedback.
External Resources
Blog posts
- Machine learning, faster (introduced me to the concept of "measure time to results, not results")
- Data Jujitsu: The art of turning data into product
- What you need to know about product management for AI
- Practical Skills for The AI Product Manager
- Product Driven Machine Learning
- Human-Centered Machine Learning
- Design in a world where Machines are Learning
- When are we going to start designing AI with purpose?
- User Research Makes Your AI Smarter
- What is the best way to write a Product Requirements Document?
Case studies
- Control and Simplicity in the Age of AI
- 150 successful machine learning models: 6 lessons learned at Booking.com
Talks
Guides
- Guidelines for Human-AI Interaction (and also check out the pretty infographic here)
- AI Meets Design
- Google's People+AI Guidebook: Designing human-centered AI products
- Designing Machine Learning
- Human-centered AI cheat-sheet
People to follow
- Michelle Carney @michellercarney works at the intersection of UX+ML and leads the MLUX meetup group.
- Jess Holbrook @jessholbrook is the co-lead of Google’s People + AI Research team; he has a ton of great articles on Medium.
- Nadia Piet @NadiaPiet works as a freelance design consultant; she put together the phenomenal aimeets.design toolkit referenced above.