Naive Bayes classification.

Naive Bayes classification methods are quite simple (in terms of model complexity) and commonly used for tasks such as document classification and spam filtering. This algorithm works well for datasets with a large amount of features (ex. a body of text where every word is treated as a feature) but it is naive in the sense that it treats every feature as independent of one another. This is clearly not the case for language, where word order matters when trying to discern meaning from a statement. Nonetheless, these methods have been used quite successfully for various text classification tasks.
Bayes' theorem
In order to discuss the Naive Bayes model, we must first cover the Bayesian principles of thinking.
- We learn about the world through tests and experiments.
- Tests are separate from events in the world. A positive test result for a disease such as cancer is not the same as a patient having cancer.
- Tests are flawed and can yield false positives (tests that detect things that don't exist) and false negatives (tests that miss something that does exist).
- Not all tests are equal, so we shouldn't believe all test evidence uniformly.
Bayes' theorem allows for us to calculate the actual probability of some event relative to the measured test probability. In other words, Bayes' theorem allows us to restate "the probability that you have cancer" as "the probability that you have cancer, given knowledge of some diagnostic test result." We can more accurately include evidence from a test by incorporating the known error of the given test.
Thus, in order to include any test evidence into our probability model, we need to know the historical accuracy of the test. For the case of a cancer screening, this would be "for all of times our test yielded a positive diagnosis, what percentage of patients actually had cancer?" Additionally, we'd need to know "what percentage of patients that did not have cancer falsely received a positive test result?"
More concretely, to calculate the probability of a patient having cancer, given a positive test diagnosis, we would combine 1) the probability that our test yields positive for a patient, given that they have cancer, with 2) the prior probability of a patient having cancer and divide by the total probability of a positive diagnosis.
$$\frac{{{\rm{P}}\left( {pos|cancer} \right){\rm{P}}\left( {cancer} \right)}}{{{\rm{P}}\left( {pos} \right)}}$$
The total probability of a positive diagnosis would include both the probability of a true positive and the probability of a false positive diagnosis.
$${\rm{P}}\left( {pos} \right) = {\rm{P}}\left( {pos|cancer} \right){\rm{P}}\left( {cancer} \right) + {\rm{P}}\left( {pos|no \hspace{1mm} cancer} \right){\rm{P}}\left( {no \hspace{1mm} cancer} \right)$$
Putting it all together, we arrive at Bayes' rule.
$${\rm{P}}\left( {cancer|pos} \right) = \frac{{{\rm{P}}\left( {pos|cancer} \right){\rm{P}}\left( {cancer} \right)}}{{{\rm{P}}\left( {pos|cancer} \right){\rm{P}}\left( {cancer} \right) + {\rm{P}}\left( {pos|no \hspace{1mm} cancer} \right){\rm{P}}\left( {no \hspace{1mm} cancer} \right)}}$$
Initially, we might assign the probability of cancer as frequency of the disease in the general population. However, after performing a test to screen for cancer, we have a better idea for that specific patients probability of having cancer. We could then perform a second test, using the updated probability of cancer, to incorporate additional evidence.
In general, we refer to the probability of an event without considering the test evidence as the prior probability and the calculated probability using Bayes' rule to incorporate a test as the posterior probability.
Bayes’ Rule is a theorem in probability theory that answers the question, "When you encounter new information, how much should it change your confidence in a belief?" - Source
Bayesian thinking allows us to update our understanding of the world incrementally as new evidence becomes available.
Derivation of Bayes' rule
It's relatively straightforward to derive the formula for Bayes' rule. First, we'll establish a defintion for the conditional probability of an event. Conditional probabilities allow us to express the probability of event $A$, given the condition that event $B$ occurs. The conditional probability of $A$ given $B$, $\rm{P}\left( {A|B} \right)$ can be calculated as the probability of $A$ and $B$ occuring, $\rm{P}\left( {A \cap B} \right)$, divided by the probability of $B$ occuring.
$$ {\rm{P}}\left( {A|B} \right) = \frac{{{\rm{P}}\left( {A \cap B} \right)}}{{{\rm{P}}\left( B \right)}} $$
I like to remember this as "out of the subset of observations where $B$ occurs, how often does $A$ occur as well?"
Using this definition of conditional probability, we can write the following:
$${\rm{P}}\left( {A|B} \right) = \frac{{{\rm{P}}\left( {A \cap B} \right)}}{{{\rm{P}}\left( B \right)}}$$
$${\rm{P}}\left( {B|A} \right) = \frac{{{\rm{P}}\left( {B \cap A} \right)}}{{{\rm{P}}\left( A \right)}}$$
The probability of $A$ and $B$ occuring is the same as the probability of $B$ and $A$ occuring.
$${\rm{P}}\left( {A \cap B} \right) = {\rm{P}}\left( {B \cap A} \right)$$
Solving the second equation for ${\rm{P}}\left( {B \cap A} \right)$, we find:
$${\rm{P}}\left( {B \cap A} \right) = {\rm{P}}\left( {B|A} \right){\rm{P}}\left( A \right)$$
We can now substitute this expression for the numerator in our first equation to arrive at the final definition of Bayes' rule.
$${\rm{P}}\left( {A|B} \right) = \frac{{{\rm{P}}\left( {B|A} \right){\rm{P}}\left( A \right)}}{{{\rm{P}}\left( B \right)}}$$
A Naive Bayes' model
We can apply Bayes' rule to the subject of classification by calculating the probability an observation belongs to some class $y$, given a feature vector $x$.
$${\rm{P}}\left( {y|{x_1},...,{x_n}} \right) = \frac{{{\rm{P}}\left( y \right){\rm{P}}\left( {{x_1},...,{x_n}|y} \right)}}{{{\rm{P}}\left( {{x_1},...,{x_n}} \right)}}$$
To keep things simple, we assume that each feature is independent of one another and that the probability of a feature being expressed depends only on the observation's class. This is known as the naive independence assumption.
$${\rm{P}}\left( {{x_i}|y,{x_1},...,{x_{i - 1}},{x_{i + 1}},...{x_n}} \right) = {\rm{P}}\left( {{x_i}|y} \right)$$
To be clear, we are stating that the probability distribution of any feature depends only on the observation's class and has no dependence on the values of other features.
Using this naive independence assumption we can simplify our first expression to consider the probability of features independently.
$${\rm{P}}\left( {y|{x_1},...,{x_n}} \right) = \frac{{{\rm{P}}\left( y \right)\prod\nolimits_{i = 1}^n {{\rm{P}}\left( {{x_i}|y} \right)} }}{{{\rm{P}}\left( {{x_1},...,{x_n}} \right)}}$$
This allows us to calculate the probability an observation belongs to a certain class given a feature vector describing the observation. Because the denominator is constant with respect to class, we can simply look at the numerator when determining the class of an observation.
$$\hat y = \arg \mathop {\max }\limits_y {\rm{P}}\left( y \right)\prod\nolimits_{i = 1}^n {{\rm{P}}\left( {{x_i}|y} \right)} $$
Simply, we'll predict an observation's class as that which has the maximum calculated probability.
In the cancer screening example I presented previously, we considered a boolean feature - the diagnosis either returns true for the disease or false. However, it's also possible to consider numerical features with a continuous range of possibilities by building a probability distribution for each feature.
Gaussian Naive Bayes
For a Gaussian Naive Bayes model, we can fit a normal distribution for each feature of all of the possible classes.
$${\rm{P}}\left( {{x_i}|y} \right) = \frac{1}{{\sqrt {2\pi \sigma_y^2} }}\exp \left( { - \frac{{{{\left( {{x_i} - {\mu_y}} \right)}2}}}{{2\sigma_y2}}} \right)$$
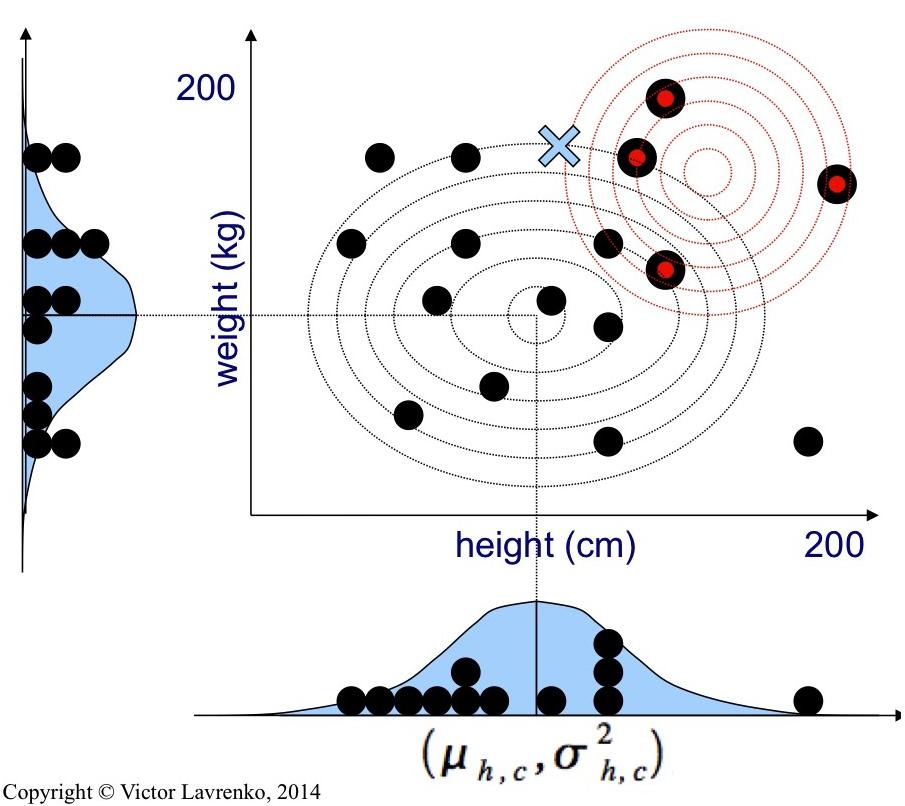
Victor Lavrenko has a nice visualization of what these Gaussian models will look like for a dataset of two classes (adult and child) each containing two features (height and weight). The Gaussian models for child heights and child weights combine to form a conic (depicted as a contour plot) and a similar combination shown in red for the adult class feature models.
{kind=link}
I like this visualization because once we leave 2-dimensional space, it becomes rather tricky to visualize what's going on, but the idea stays the same.
Summary
In summary, Bayes' theorem provides a statistical framework for incorporating test evidence into our probabilistic viewpoint of events. We can apply Bayes' theorem to classification tasks within machine learning to calculate the probability of an observation belonging to each of the possible classes, given a feature vector that describes the observation.
It's important to note that although Naive Bayes' methods can work fairly well for predicting class, the actual probabilities calculated are generally not too accurate. This is due to the fact that we often incorrectly assume independence of features for the sake of convenience.